[a revolution in mass-scale content distribution]
|
|
the power of broadcast
[a revolution in mass-scale content distribution] |
|
a comparison with BitTorrent BitTorrent is a system that spreads the load of file distribution among downloaders, reducing (or completely eliminating) bandwidth usage on the content server. The server splits the content file into chunks and creates a map file that describes each chunk. Downloaders retrieve this map file and then connect to a "tracker" server. The tracker maintains a list of downloaders that already have each chunk. Thus, a downloader can obtain the chunks that it needs from other downloaders and in turn serve back the chunks that it already has. since BitTorrent's focus is on load balancing in the distribution of high-demand content (in other words, reducing the "Slashdot effect"), it might be seen as the closet "competitor" to konspire2b. Obtaining different pieces of a file from different sources to increase download rates is known as "swarming". Upon seeing the non-swarmed distribution tree used by konspire2b, many people ask, "why not swarm?" or even, "why not just use BitTorrent in the first place?"---some explanation is certainly needed. in systems (such as eDonkey) where many nodes have a file and only a few nodes are downloading it, swarming makes sense---downloading from more than one source will certainly increase download rates. However, in a BitTorrent peer network, everyone that has pieces of the file is also trying to obtain the file. Does swarming really make sense in this kind of network? the following quote is from the BitTorrent website (their boldface): The key to cheap file distribution is to tap the unutilized upload capacity of your customers. It's free. Their contribution grows at the same rate as their demand, creating limitless scalability for a fixed cost.the reality of the situation is that most downloaders are using asymmetric connections with far greater download capacity than upload capacity---download rates can be more than ten times faster than upload rates. Thus, the contribution of downloaders does not grow at the same rate as their demand: as an ADSL downloader, I want 192 KiB/second downloads, while I can only supply 16 KiB/second uploads (total) to other downloaders. As more ADSL downloaders request the file, their demand grows 12 times faster than their contribution. in a recent paper (pdf) on economic models applied to BitTorrent, the author makes the astute observation that the total download rate throughout the BitTorrent peer network cannot exceed the total upload rate. Thus in a fair system, if every downloader has ADSL, and everyone is currently in the middle of downloading, then everyone would have a download rate equal to their upload rate. If this is the case, what is the point of "swarming" separate file chunks in attempt to increase download rates? If every downloader simply picked a peer node to upload the file to, the download rates would be maximized---no swarming necessary. of course, BitTorrent counts on downloaders staying online for a while after their download is finished. With this added bandwidth, most ADSL downloaders are likely to see download rates that are slightly higher than their upload rate. However, this is not a dependable source of extra bandwidth. according to conservation of bandwidth in BitTorrent, we can only count on each downloader uploading the file to at most one other downloader before it disconnects. This pessimistic assumption makes BitTorrent's worst-case content distribution properties relatively easy to analyze. analysis of BitTorrent as a simple example, consider a content file that is split into three chunks by BitTorrent. Each downloader, according to our pessimistic assumption, transfers the file to one other downloader before it disconnects. A downloader can start uploading to another downloader after it has received at least one chunk of the file. Since its download rate equals its upload rate, it will have another chunk ready to upload by the time time it has finished uploading the first chunk. If we assume that all downloaders have ADSL, there is no gain from a downloader uploading to more than one other downloader at a time: the other downloader can saturate its upload capacity completely. Suppose that alice is the first downloader: she downloads directly from the original server. bob can be thought of as the "second" downloader, and he downloads from alice. Since alice is saturating the server's upload capacity with her download, bob must wait for alice to obtain at least one block before he can download from anyone. alice has unused upload capacity at first, but she has no blocks to upload. If we assume it takes 1 timestep to receive a chunk (and therefore 3 timesteps to receive the entire file), the interaction between alice, bob, and the server can be clarified by this table:
if we expand our example to a larger group of receivers, we get a distribution tree made up of cascades. In the following diagram, the server is represented by a circle, and each rectangle represents a downloader. Time increases as you move down in the figure. The top of a rectangle represents when a downloader starts receiving a file, and the bottom of the rectangle represents when a downloader finishes receiving a file. Thus, each downloader rectangle is three "units" tall. 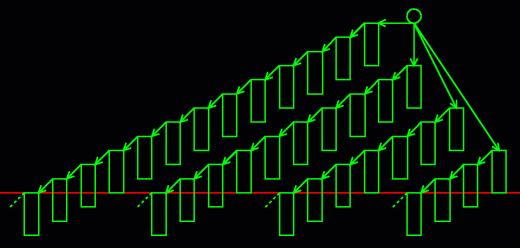 for comparison, the following diagram shows a similar distribution tree for konspire2b. Again, time increases as you go down in the figure, and rectangles represent start and end times for receiver downloads.  at this point, it looks like BitTorrent wins the race: it reaches 22 receivers in the time it takes konspire2b to reach 15. However, the following table shows why bounds can be tricky to analyze. Nb(t) represents the number of downloaders reached by BitTorrent in t content timesteps, and Nk(t) represents the number reached by konspire2b:
keep in mind that the BitTorrent tree used in this analysis is the optimal tree if we assume that each downloader stays online long enough to transmit the complete file to one other downloader. Even if this assumption holds, the random nature of a BitTorrent network is likely to produce a tree that is less than optimal (with worse performance than what we derived in this analysis). We called our assumption about downloaders a "pessimistic" assumption earlier, but it is in some ways an optimistic assumption: downloaders that watch the progress bar are likely to disconnect from the network as soon as their download completes and before their node has a chance to finish the equivalent of a complete file upload to other downloaders. Other downloaders (for example, those that are away from their machines) are likely to remain connected to the network long after their download completes, so they might upload the file to other downloaders more than once. The longer downloaders stay online, the more BitTorrent's performance approaches konspire2b's performance. konspire2b uses a completely different model for user interaction---with this model, most receivers are likely to remain online until the broadcast is complete network-wide. Each channel in konspire2b contains a series of valuable files, not just a single download. Users that disconnect shortly after a download completes are likely to miss future downloads that are of equal in value to their current download. realistic numbers (constants matter) one complaint about the above analysis is that we set c=3 in our equation for Nb(t). The constant c represents the number of chunks in a file, and very few files have only 3 chunks. If we instead set c=1,000,000, the results are quite different: BitTorrent transfers the complete file to millions of people in only a few timesteps, and konspire2b is left in the dust. However, each chunk is represented by a 20-byte hash string in the BitTorrent map file, so breaking a file into 1,000,000 chunks would result in a 20 MiB map file. Since every downloader gets this map file directly from the server, files with this many chunks are not practical. as a real-world example, we can use the Mandrake GNU/Linux distribution. The 650 MiB file is broken into 256 KiB chunks, so there are just over 2500 of them. Thus, we can set c=2500. The following table shows the number of receivers reached by each system in a given number of content timesteps. Keep in mind that here, a content timestep is the time it takes to upload Mandrake over an ADSL connection, or roughly 11 hours.
in today's world, a billion receivers sounds unreasonable, but a million receivers does not. However, konspire2b is only 30% faster for a million receivers. What about 10 million receivers? konspire2b can reach this many in 24 timesteps, while BitTorrent would take 90 timesteps (also not shown in the table). For that large of an audience, konspire2b is 73% faster. who really cares about the numbers when they get this big? We do. We designed konspire2b so that it could scale to reach enormous audiences. why not use BitTorrent? given the above analysis, the answer is simple: using BitTorrent would prohibit the kind of mass-scale content distribution possible with konspire2b distribution trees. If you want to get your content out to a large audience as quickly as possible, konspire2b is the system of choice. should BitTorrent and konspire2b be seen as competing systems? BitTorrent is designed to reduce the strain on a web server in the distribution of a file. konspire2b is designed to allow a sender to deliver a series of fresh files to a large group of receivers over time. Whether these systems are even attacking the same problem is a matter of much debate. |